- آموزش امواج رابرت بالان الیوت
- cryptocurrency بعدی برای منفجر شدن در سال 2022
- با افزایش سهم لوکس ، براساس آخرین داده های قیمت معاملات Kelley Blue Book ، قیمت های جدید در ماه نوامبر رکورد بالایی دارد
- FP Markets Account Demo: چگونه می توان از آن با تجارت استفاده کرد؟- یک آموزش سریع
- سبد سرمایه گذاری خود را بسازید
- 15 قانون معاملاتی ویکتور اسپراندو برای جلوگیری از اشتباه و دستیابی به بازدهی چشمگیر
- نحوه خرید سهام Google: سرمایه گذاری در سهام غول فناوری
- رالی بزرگ Smallcap. 5 رهبر و عقب مانده برتر.
- پنج اشتباه بزرگ از سرمایه گذاران "Do-It-Yourour"
- مسیرهای عصبی

آخرین مطالب
امکانات وب


عدم قطعیت ها در بهینه سازی سیستم های فرآیندی، مانند عدم قطعیت در فناوری های فرآیند، قیمت ها و خواسته های مشتری، گسترده هستند. در این مقاله، مفاهیم اساسی و پیشرفت های اخیر یک چارچوب ریاضی خنثی به نام «برنامه نویسی تصادفی» و کاربردهای آن در حل مسائل مهندسی سیستم های فرآیند تحت عدم قطعیت را مرور می کنیم. این بررسی قصد دارد هم یک آموزش برای مبتدیان بدون تجربه قبلی و هم یک مرور سطح بالا از پیشرفت های فعلی را برای متخصصان مهندسی سیستم های فرآیندی و برنامه نویسی تصادفی ارائه دهد. فرمول بندی ها و الگوریتم های ریاضی برای برنامه ریزی تصادفی دو مرحله ای و چند مرحله ای با مثال های گویا از صنایع فرآیندی بررسی می شوند. تفاوت بین برنامه ریزی تصادفی تحت عدم قطعیت برون زا و عدم قطعیت درون زا مورد بحث قرار می گیرد. مفاهیم و چندین روش مبتنی بر داده برای تولید درخت های سناریو نیز بررسی می شوند.
1. معرفی
برنامه نویسی تصادفی ، همچنین به عنوان بهینه سازی تصادفی شناخته می شود (Birge and Louveaux ، 2011) ، یک چارچوب ریاضی برای مدل سازی تصمیم گیری تحت عدم اطمینان است. منشاء برنامه نویسی تصادفی به دهه 1950 باز می گردد که جورج بی دانتزیگ ، به عنوان پدر الگوریتم Simplex برای برنامه نویسی خطی شناخته شد ، مقاله پیشگام "برنامه نویسی خطی تحت عدم اطمینان" را نوشت (دانتزیگ ، 1955). در این مقاله پیشگام ، دانتزیگ یکی از انگیزه های توسعه چارچوب مدل سازی برنامه نویسی تصادفی را به عنوان "شامل موارد خواسته های نامشخص برای مشکل تخصیص بهینه ناوگان حامل به مسیرهای هواپیمایی برای برآورده کردن توزیع تقاضای پیش بینی شده توصیف کرد."یکی دیگر از کارهای اولیه در مورد برنامه نویسی تصادفی را می توان در بیل (1955) یافت. از آن به بعد ، برنامه نویسی تصادفی به یک زمینه اصلی تحقیقات برای برنامه نویسی ریاضی و جامعه تحقیقاتی عملیات تبدیل شده است. تعداد قابل توجهی از تحولات نظری و الگوریتمی توسط ریاضیدانان انجام شده است ، که در کتابهای درسی کلاسیک خلاصه شده اند (Birge and Louveaux ، 2011 ؛ Shapiro et al. ، 2014). با افزایش بلوغ روشهای الگوریتمی و محاسباتی ، برنامه نویسی تصادفی برای طیف گسترده ای از مشکلات اعمال شده است (والاس و زیمبا ، 2005) از جمله برنامه ریزی مالی ، تولید برق ، مدیریت زنجیره تأمین ، کاهش تغییرات آب و هوا و کنترل آلودگی ،در میان بسیاری دیگر
مهندسی سیستم های فرآیند (PSE) منطقه مهندسی شیمی است که بر توسعه و کاربرد مدل سازی و روشهای محاسباتی برای شبیه سازی ، طراحی ، کنترل و بهینه سازی فرآیندها متمرکز است (Sargent ، 2005). عدم قطعیت در بهینه سازی سیستم های فرآیند ، مانند قیمت و خلوص مواد اولیه ، تقاضای مشتری ، بازده راکتورهای خلبان و غیره شیوع دارد. ازدواج برنامه نویسی تصادفی با PSE به نظر می رسد یک اتحاد طبیعی است. با این حال ، اولین کاربرد برنامه نویسی تصادفی در PSE یک دهه پس از آن صورت گرفت که دانتزیگ اولین مقاله خود را نوشت. اولین مقاله ای که می توانیم پیدا کنیم مقاله کیتلل و واتسون (1966) است که نویسندگان از برنامه نویسی تصادفی برای طراحی بهینه تجهیزات PROCES تحت پارامترهای نامشخص استفاده می کردند. دلیل اینکه محققان در PSE برای استفاده از برنامه نویسی تصادفی ممنوع است این است که منابع محاسباتی در روزهای اولیه محدود بوده و مدل های برنامه نویسی تصادفی برای حل آن بسیار دشوارتر از همتایان قطعی آنها هستند. پس از دهه 1990 ، با بهبود نرم افزار برنامه نویسی ریاضی تجاری ، به عنوان مثال ، حل کننده هایی مانند CPLEX (لیما ، 2010) و سخت افزار رایانه ، علاقه بیشتری به استفاده از برنامه نویسی تصادفی برای پردازش برنامه های سیستم ها وجود دارد. در شکل 1 ، ما تعداد مقالات را با برنامه نویسی تصادفی به عنوان موضوع اصلی منتشر شده در چهار ژورنال و کنفرانس های اصلی PSE ، رایانه ها و مهندسی شیمی ، مهندسی شیمی با کمک رایانه ، تحقیقات شیمی صنعتی و مهندسی و مجله Aiche ، از 1990 تا سپتامبر بررسی می کنیم. اول ، 2020. رشد قابل توجهی در تعداد مقالات در این افق زمانی مورد بررسی وجود دارد که حدود 30 مقاله در سال پس از سال 2010.
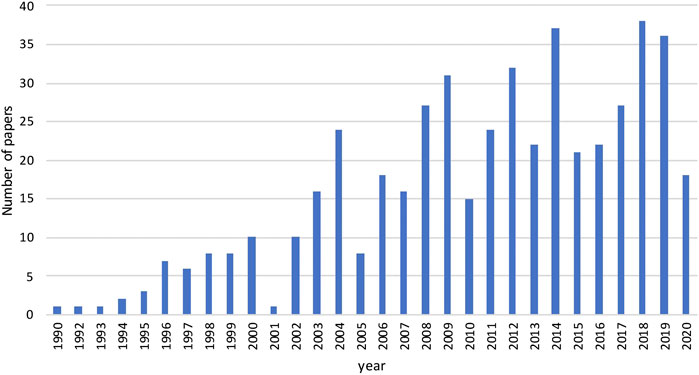
شکل 1 . تعداد مقالات منتشر شده در مجلات از جمله رایانه ها و مهندسی شیمی ، مهندسی شیمی به کمک رایانه ، تحقیقات شیمی صنعتی و مهندسی و مجله AICHE از 1990 تا اول سپتامبر 2020 (داده های به دست آمده از وب علوم).
برنامه های برنامه نویسی تصادفی نیز در جامعه PSE گسترده است. در جدول 1 ، برخی از مقالات بسیار استناد شده از چهار ژورنال مربوط به PSE که از برنامه نویسی تصادفی استفاده می کنند گزارش شده است. برنامه ها دارای مقیاس زمانی بسیار گسترده ای هستند ، از مشکلات طراحی و برنامه ریزی بلند مدت گرفته تا مشکلات برنامه ریزی کوتاه مدت و کنترل. از نظر بخش های صنعتی ، مقالات ذکر شده در جدول 1 هر دو بخش صنعتی سنتی مانند نفت ، گاز طبیعی ، دارویی ، شیمیایی و غیره و بخش های جدید مانند سوخت های زیستی ، ضبط کربن و غیره را دارند. در این برنامه ها شامل قیمت ها ، تأمین و غلظت مواد اولیه ، تقاضای تولیدات نهایی ، فن آوری های فرآیند ، نتایج آزمایش بالینی است.
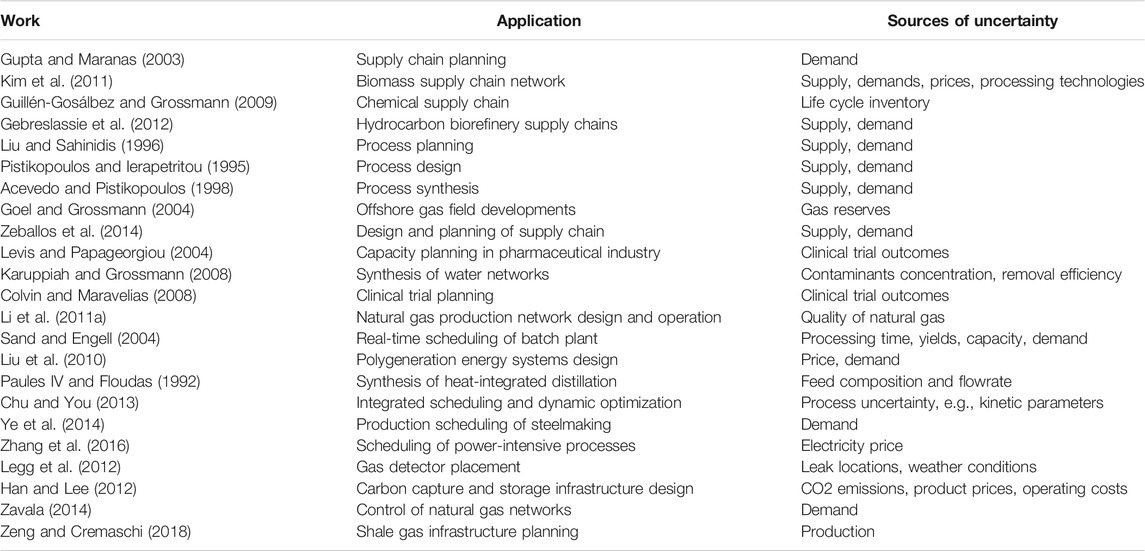
میز 1 . خلاصه آثار نماینده که از برنامه نویسی تصادفی برای برنامه های PSE استفاده می کنند.
با توجه به محبوبیت روزافزون برنامه نویسی تصادفی در جامعه PSE ، این مقاله با هدف ارائه نمای کلی از تکنیک های اساسی مدل سازی و الگوریتم ها برای برنامه نویسی تصادفی و همچنین توصیف سطح بالا از مشارکت های اخیر توسط انجمن PSE به غیر expert ارائه می شود. حضار. برای خوانندگان علاقه مند به تحولات ریاضی اخیر در برنامه نویسی تصادفی ، ما به مقالات بررسی توسط Sahinidis (2004) اشاره می کنیم. Küçükyavuz and Sen (2017) ؛تورس و همکاران.(2019).
این مقاله به شرح زیر سازماندهی شده است. در بخش 2 ، ما یک مرور کلی از برنامه نویسی ریاضی و بهینه سازی تحت عدم اطمینان ارائه می دهیم. در بخش 3 مفاهیم ، فرمولاسیون ریاضی و الگوریتم های برنامه نویسی تصادفی دو مرحله ای را معرفی می کنیم. در بخش 4 ، ما یک برنامه نویسی تصادفی دو مرحله ای ، برنامه نویسی تصادفی چند مرحله ای را معرفی می کنیم. در بخش 5 ، تکنیک های برنامه نویسی تصادفی چند مرحله ای تحت عدم اطمینان درون زا بررسی می شود. در بخش 6 ، ما روشهای داده محور را برای تولید درختان سناریو مرور می کنیم. نتیجه گیری را در بخش 7 نتیجه می گیریم.
2 بهینه سازی تحت عدم اطمینان
فرآیند تصمیم گیری معمولاً به عنوان یک مشکل بهینه سازی مدل می شود. یک مشکل بهینه سازی عمومی به شکل موجز زیر در Eq نشان داده شده است. 1 در جایی که ما برخی از متغیرهای مداوم x را داریم ، برای نشان دادن تصمیمات گرفته شده ، (به عنوان مثال تصمیم گیری در مورد یک راکتور) ، 0-1 متغیرهای y برای نشان دادن گزینه های گسسته ، (به عنوان مثال یک راکتور معین را انتخاب کنید یا نه) ، یک تابع هدف fبرای به حداقل رساندن یا به حداکثر رساندن ، (به عنوان مثال برای به حداقل رساندن هزینه کل) ، و برخی از محدودیت های g ، h ، که متغیرها باید برآورده شوند ، (به عنوان مثال تعادل جرم).
متغیرهای x متغیرهای مداوم با ابعاد n x هستند که می توانند مقادیر واقعی را به خود اختصاص دهند. متغیرهای y متغیرهای باینری با ابعاد n y هستند که فقط می توانند مقادیر 0 یا 1 را بگیرند. متغیرهای باینری معمولاً برای نشان دادن روابط منطقی یا انتخاب ها استفاده می شوند ، به عنوان مثال ، چه نصب یک گیاه شیمیایی معین یا نه. وکتور θ پارامترهای درگیر در مشکل بهینه سازی ، مانند تقاضای محصول ، هزینه های واحد برخی از فرآیندها را نشان می دهد. اگر فرض کنیم که این پارامترها با اطمینان شناخته شده اند ، مشکل Eq. 1 یک مشکل بهینه سازی قطعی است. یک مشکل بهینه سازی قطعی بسته به اشکال F ، G ، H ، X ، Y می تواند به چند دسته طبقه بندی شود.
• برخی از F ، G ، H ، توابع غیرخطی هستند. مشکل Eq. 1 یک برنامه غیرخطی مخلوط (MINLP) است.
• F ، G ، H همه توابع خطی هستند. مشکل Eq. 1 به یک برنامه خطی مخلوط مخلوط (MILP) تبدیل می شود.
• برخی از F ، G ، H ، توابع غیرخطی هستند و هیچ متغیر Y وجود ندارد ، یعنی N Y = 0. مشکل Eq. 1 به یک برنامه غیرخطی (NLP) تبدیل می شود.
• F ، G ، H ، توابع خطی هستند و هیچ متغیر Y وجود ندارد ، یعنی N Y = 0. مشکل Eq. 1 به یک برنامه خطی (LP) تبدیل می شود.
چهار برنامه مختلف ریاضی ، MINLP ، MILP ، NLP ، LP ، بسته به ماهیت مشکل انتخاب شده اند. برای مشکلات در مهندسی شیمی ، معادلات غیرخطی اغلب برای توصیف رفتار ترمودینامیکی یا جنبشی استفاده می شود. از متغیرهای عدد صحیح می توان برای توصیف مشکلات سنتز فرآیند استفاده کرد ، به عنوان مثال ، یک متغیر باینری می تواند توصیف کند که آیا یک ستون تقطیر داده شده وجود دارد یا در یک صفحه شیمیایی وجود ندارد. برای درمان دقیق روشهای بهینه سازی قطعی ، ما به کتاب درسی توسط گروسمن (2021) مراجعه می کنیم.
در مدلهای بهینه سازی قطعی ، پارامترهای θ فرض می شود که شناخته شده است. با این حال ، در عمل ، عدم قطعیت ها به دلیل اندازه گیری نادرست ، خطای پیش بینی یا عدم اطلاعات در سیستم های فرآیند شیوع دارند. به عنوان مثال ، عدم قطعیت در مدیریت زنجیره تأمین می تواند ناشی از تقاضای آینده مشتری ، اختلال در شبکه بالقوه یا حتی گسترش یک بیماری همه گیر باشد. عدم در نظر گرفتن عدم قطعیت در فرآیند تصمیم گیری ممکن است منجر به راه حل های زیر حد متوسط یا حتی غیرقابل نفوذ شود. برای محافظت در برابر عدم قطعیت در سیستم های فرآیند ، چندین چارچوب ریاضی توسط جامعه PSE از جمله برنامه نویسی تصادفی ، برنامه نویسی با محدودیت شانس (لی و همکاران ، 2008) و بهینه سازی قوی استفاده شده است.(Lappas and Gounaris ، 2016). این سه رویکرد در درجه های خودداری از ریسک و روشهای توصیف عدم قطعیت متفاوت است. برنامه نویسی تصادفی (SP) یک رویکرد بی طرف ریسک است ، که به دنبال بهینه سازی نتیجه مورد انتظار در مورد توزیع احتمال شناخته شده است. برنامه نویسی محدود شده با شانس را می توان به عنوان حل یک برنامه تصادفی با برخی از محدودیت های احتمالی دانست ، که نشان می دهد برخی از محدودیت ها با پارامترهای نامشخص از سطح معینی از احتمال راضی هستند. به عنوان مثال ، یک محدودیت شانس می تواند مشخص کند که بودجه/هزینه ای که نباید از آستانه خاصی تجاوز کند. برنامه نویسی محدود کننده احتمال انعطاف پذیری مدل سازی را برای مقابله با مسائل مربوط به قابلیت اطمینان و ارتباطات مهمی با مدیریت ریسک ارائه می دهد. بهینه سازی قوی یکی دیگر از رویکردهای ریسک پذیر است ، که به دنبال بهینه سازی "بدترین حالت" در یک مجموعه عدم اطمینان از پیش تعریف شده است. مشکلات بهینه سازی قوی به طور معمول شامل نوع حداقل عملگرها است. خلاصه ای از سه روش در جدول 2 نشان داده شده است.

جدول 2خلاصه برنامه نویسی تصادفی ، برنامه نویسی محدود شده با شانس و بهینه سازی قوی.
علاوه بر این سه رویکرد ، تعدادی از چارچوب های ریاضی برای مدل سازی تصمیم گیری تحت عدم اطمینان ، مانند فرآیند تصمیم گیری مارکوف (MDP) وجود دارد. پاول (2019) 15 جامعه را در بهینه سازی تحت عدم اطمینان در یک چارچوب واحد متحد می کند. مرور همه 15 رویکرد خارج از محدوده این مقاله است. خوانندگان علاقه مند می توانند به مقالات مربوطه مراجعه کنند (پاول ، 2019 ، پاول ، 2016).
3 برنامه نویسی تصادفی دو مرحله ای
برنامه نویسی تصادفی دو مرحله ای یک مورد خاص از برنامه نویسی تصادفی است. در این بخش ، فرمولاسیون های ریاضی ، الگوریتم ها و نمونه های مصور برای برنامه نویسی تصادفی دو مرحله ای را شرح می دهیم.
3. 1 برنامه های خطی مخلوط تصادفی دو مرحله ای
برای سادگی ارائه ، ما مشکلات MILP تصادفی را در نظر می گیریم.
3. 1. 1 فرمول ریاضی
در برنامه نویسی تصادفی ، فرض بر این است که توزیع احتمال پارامترهای نامشخص پیشینی شناخته شده است. عدم قطعیت ها معمولاً با برخی از تحقق گسسته از پارامترهای نامشخص به عنوان تقریب توزیع احتمال واقعی مشخص می شوند. به عنوان مثال ، تحقق تقاضا برای یک محصول می تواند سه مقدار مختلف داشته باشد که به ترتیب نشان دهنده تقاضای زیاد ، متوسط و کم است. هر تحقق به عنوان یک سناریو تعریف می شود. هدف برنامه نویسی تصادفی بهینه سازی مقدار مورد انتظار یک عملکرد هدف ، (به عنوان مثال هزینه مورد انتظار) در تمام سناریوها است.
یک مورد خاص از برنامه نویسی تصادفی ، برنامه نویسی تصادفی دو مرحله ای است (شکل 2). به طور خاص ، تصمیمات مرحله یک در ابتدای دوره "در اینجا و اکنون" گرفته می شود و پس از آن با حل عدم اطمینان دنبال می شوند. مرحله دو تصمیمات یا تصمیمات مراجعه به "صبر کنید و ببینید" به عنوان اقدام اصلاحی در پایان دوره. یک نوع متداول برنامه تصادفی دو مرحله ای ، برنامه خطی مخلوط و مشخص است که در Eq ارائه شده است. 2. ω مجموعه سناریوها است. τωاحتمال سناریو ω است. X تصمیمات مرحله اول را نشان می دهد. حرفωتصمیمات مرحله دوم را در سناریو ω نشان می دهد. عدم قطعیت ها در ماتریس ها (بردارها) ، w منعکس می شوندω، ساعتω، tωدر Eq نشان داده شده است. 2. در ادبیات ، wω"ماتریس مراجعه" نامیده می شود. حرفω"ماتریس فناوری" نامیده می شود. در سمت راست شکل 2 ، نمونه ای از "درخت سناریو" که دارای سه سناریو با H نامشخص استωبرای نشان دادن تحقق عدم قطعیت ها در سمت راست استفاده می شود.
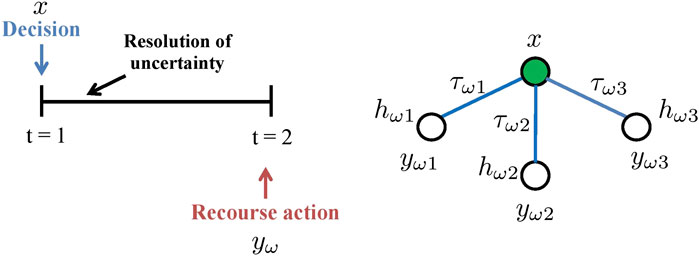
شکل 2 . مشکل دو مرحله ای: بازنمایی مفهومی (سمت چپ) ؛درخت سناریو (سمت راست) که در آن x تصمیمات مرحله اول را نشان می دهد ، y ω نشانگر مرحله دو تصمیم برای سناریو ω است. τ ω ، H ω به ترتیب احتمال و سمت راست دست راست سناریو ω را نشان می دهد.
برای مشکل Eq. 2 ، هر دو تصمیم مرحله اول و دوم با دودویی مختلط هستند. اجازه دهید من =<1,2 , … , n>مجموعه شاخص از تمام متغیرهای مرحله اول باشد. I 1 ⊆ من زیر مجموعه شاخص های متغیرهای مرحله اول باینری است. اجازه دهید j =<1,2 , … , m>مجموعه شاخص از تمام متغیرهای مرحله دوم باشید. J 1 ⊆ J زیر مجموعه ای از شاخص های متغیرهای مرحله دوم باینری است. X U B یک بردار است که نشان دهنده مرز بالایی از تمام متغیرهای مرحله اول است. y ω u b یک بردار است که نشان دهنده مرز بالایی از تمام متغیرهای مرحله دوم است. مشکل توصیف شده توسط Eq. 2 یک برنامه خطی مخلوط دو مرحله ای است (TS-MILP). اگر هر دو j1و من1مجموعه های خالی هستند ، Eq. 2 به یک مشکل برنامه نویسی خطی تصادفی دو مرحله ای (TS-LP) کاهش می یابد. Eq2 اغلب به عنوان معادل قطعی یا شکل گسترده برنامه تصادفی دو مرحله ای از زمان Eq گفته می شود. 2 را می توان به همان روشی حل کرد که گویی ما در حال حل یک مشکل بهینه سازی قطعی هستیم.
min c ⊤ x + ∑ Ω ∈ ω τ ω d ω ⊤ y ω s. t. a x ≤ b w ω y ω ≤ h ω - t ω x ∀ ω ∈ ω x ∈ X ، x =
3. 1. 2 مشکل شبکه فرآیند
برای نشان دادن چگونگی استفاده از برنامه نویسی تصادفی دو مرحله ای برای یک مشکل مهندسی سیستم فرآیند ، ما یک مشکل طراحی شبکه فرآیند را تحت عدم اطمینان تقاضا ارائه می دهیم. از طریق این مثال ، ما همچنین هدف این است که نشان دهیم که راه حل های به دست آمده از یک برنامه تصادفی می تواند با حل یک مشکل قطعی که پارامترهای نامشخص در مقدار مورد انتظار آنها ثابت هستند ، متفاوت باشد.
در نظر بگیرید که یک ماده شیمیایی C تولید کنید که می تواند با هر دو فرآیند 2 یا فرآیند 3 تولید شود ، که هر دو از مواد شیمیایی B به عنوان مواد اولیه استفاده می کنند. B را می توان از یک شرکت دیگر خریداری کرد و/یا با فرآیند 1 که از A به عنوان ماده اولیه استفاده می کند ، ساخته شده است. تقاضای C شیمیایی ، که به عنوان D مشخص می شود ، منبع عدم اطمینان است. روبنا شبکه فرآیند در شکل 3 نشان داده شده است که تمام گزینه های ممکن برای نصب این گیاه شیمیایی را تشریح می کند. گزینه های دیگر عبارتند از: 1) هر سه فرآیند انتخاب شده اند. 2) یک زیر مجموعه واقعی از سه فرآیند انتخاب شده است. 3) هیچ یک از سه فرآیند انتخاب نشده است.
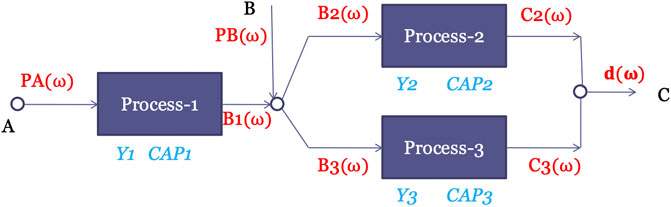
شکل 3. روبنا برای مشکل شبکه فرآیند.
پس از چارچوب تحقق زمان شرح داده شده در شکل 2 ، مشکل به عنوان یک برنامه تصادفی دو مرحله ای تدوین می شود. قبل از تحقق تقاضا برای محصول و گیاه شروع به تولید می کند. بنابراین ، تصمیمات مرحله اول تصمیمات سرمایه گذاری در مورد سه فرآیند است که شامل متغیرهای باینری y استمنبرای نشان دادن اینکه آیا فرآیند I انتخاب شده و درپوش متغیرهای مداوم استمنبرای نشان دادن ظرفیت فرآیند I برای i = 1 ، 2 ، 3. فرض می کنیم که پس از نصب گیاه ، تقاضا برای محصول محقق می شود. بر اساس تحقق تقاضا ، اقدامات متفاوتی در مورد نحوه کار با گیاه نصب شده می تواند انجام شود ، یعنی تصمیمات مرحله دوم جریان مواد است. ما سناریوها را به عنوان ω بیان می کنیم و صریحاً وابستگی تصمیم مرحله دوم به آنها را با ارائه آنها به عنوان توابع ω بیان می کنیم.
متغیرهای PA (ω) ، PB (ω) به ترتیب میزان خرید مواد شیمیایی A و B را نشان می دهند. سایر جریان های مواد برای شیمیایی B و C در ساختار در شکل 3 نشان داده شده است. فرمولاسیون MILP به شرح زیر نشان داده شده است.
حداکثر - (10 y 1 + 15 y 2 + 20 y 3 + cap 1 + 1. 5 cap 2 + 2 cap 3) + e d (ω) ∼ ℙ [ - 4. 5 p a (ω) - 9. 5 p b (ω) - 0. 5 p a(Ω) - 0. 5 B 2 (Ω) - 0. 5 B 3 (Ω) + 25 C 2 (Ω) + 25 C 3 (Ω)] (3a)
هدف حداکثر رساندن سود مورد انتظار است ، که شامل درآمد مورد انتظار به دست آمده از فروش محصول نهایی [25 c 2 (ω) + 25 c 3 (ω)] ، منهای کل هزینه ای است که شامل ثابت است (10 y 1 + 15 y2 + 20 y 3) و متغیر (CAP 1 + 1. 5 CAP 2 + 2 CAP 3) هزینه های سرمایه گذاری در مرحله یک ، هزینه مورد انتظار برای خرید مواد شیمیایی A و B در سناریوهای مختلف [4. 5 P A (ω) + 9. 5 P B (ω)]) هزینه عملیاتی مورد انتظار [0. 5 p a (ω) + 0. 5 b 2 (Ω) + 0. 5 b 3] ، که متناسب با مقدار ورودی به هر فرآیند است ، یعنی p a (ω) ، b 2 (Ω) ،B 3 (Ω).
فرض کنید ما یک مشکل 3-scenario داریم که در آن تقاضای d (ω) مقادیر d (ω 1) = 8 ، d (ω 2) = 10 ، d (ω 3) = 12 را با احتمال τ (ω 1) = 0. 25 می گیرد.، τ (ω 2) = 0. 5 ، τ (ω 3) = 0. 25. تصمیمات بهینه مرحله اول انتخاب فرآیندهای 1 و 3 با ظرفیت های 11. 70 و 12. 63 به ترتیب است که در شکل 4I نشان داده شده است. توجه داشته باشید که تصمیمات مرحله اول "در اینجا و اکنون" گرفته می شود و بنابراین برای هر سه سناریو یکسان است. با این حال ، تصمیمات مختلف مرحله دوم برای سناریوهای مختلف اتخاذ می شود همانطور که در شکل 4II نشان داده شده است. هنگامی که تقاضا کم D (ω 1) = 8 باشد ، فرآیندهای 1 و 3 با ظرفیت کامل خود کار نمی کنند. برای D (ω 2) = 10 ، فرآیند 1 با ظرفیت کامل کار می کند اما فرآیند 3 نیست. برای D (ω 3) = 12 ، هر دو فرآیند نصب شده با ظرفیت کامل کار می کنند. مواد شیمیایی A که توسط فرآیند 1 تولید می شود قادر به برآورده کردن نیاز فرآیند نیست. بنابراین ، شیمیایی اضافی B باید در صورت زیاد تقاضا از سایر فروشندگان خریداری شود. سود مورد انتظار برنامه تصادفی 117. 22 است. این مقدار بهینه از برنامه تصادفی ، مقدار مشکل مراجعه (RP) در ادبیات نامیده می شود (Birge and Louveaux ، 2011) (RP = 117. 22).
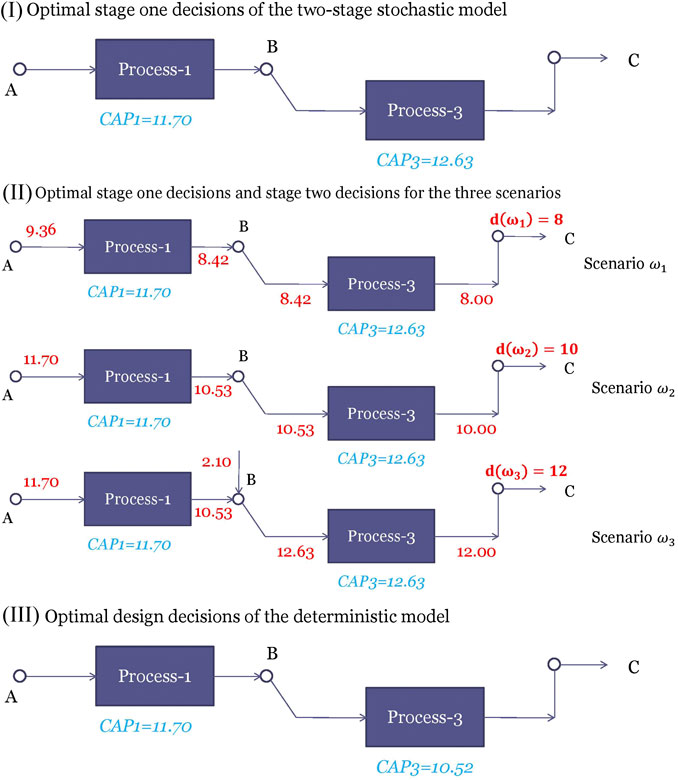
شکل 4(i) نشانگر تصمیمات بهینه مرحله اول برنامه تصادفی دو مرحله (II) تصمیمات مرحله بهینه یک را توصیف می کند و مرحله دو تصمیم تحت سناریوهای ω 1 ، ω 2 ، ω 3 (III) نشانگر تصمیمات بهینه طراحی تعیین کننده استمدل.
به غیر از استفاده از برنامه نویسی تصادفی ، یک روش جایگزین برای حل مدل قطعی است که در آن تقاضا با میانگین مقدار آن ثابت است ، یعنی تنظیم D = 10. راه حل بهینه برای این مدل قطعی انتخاب فرآیندهای 1 و 3 با ظرفیت های 11. 70 است ،و 10. 52 ، به ترتیب همانطور که در شکل 4III نشان داده شده است. تنها تفاوت از محلول تصادفی این است که ظرفیت فرآیند 3 کمتر می شود. دلیل این امر این است که مدل قطعی "از سناریوی تقاضای زیاد" بی خبر است و بنابراین ظرفیت فرآیند 3 را فقط برای برآورده کردن d = 10 کافی می کند. اما اگر از راه حل قطعی برای d = 12 استفاده کنیم ، نتیجه خواهد گرفت. در فروش از دست رفتهما می توانیم راه حل های مرحله اول را برای راه حل های بهینه برطرف کنیم و با حل هر مرحله دو مرحله به طور جداگانه ، نحوه عملکرد آن در سه سناریو را ارزیابی کنیم. سود مورد انتظار 114. 20 به دست می آید. این مقدار نتیجه مورد انتظار استفاده از محلول مورد انتظار (EEV) نامیده می شود.
یک متریک کمی برای ارزیابی مقدار اضافی ایجاد شده توسط برنامه نویسی تصادفی در مقایسه با حل مدل قطعی در میانگین ، مفهومی به نام مقدار راه حل تصادفی (VSS) است (Birge and Louveaux ، 2011). اگر مشکل یک مشکل حداکثر باشد ، VSS به عنوان تعریف می شود ،
بنابراین ، مقدار محلول تصادفی برای مشکل شبکه فرآیند 117. 22 - 114. 20 = 3. 02 است.
3. 1. 3 الگوریتم های تجزیه کلاسیک
یک گزینه برای حل مشکلات MILP تصادفی که توسط Eq شرح داده شده است. 2 برای حل مسئله معادل قطعی Eq است. 2 به طور مستقیم با استفاده از حلال های تجاری مانند CPLEX ، GUROBI. با این حال ، حل معادله. 2 به طور مستقیم می تواند هنگامی که تعداد سناریوها زیاد باشد ، ممنوع باشد زیرا زمان محاسباتی می تواند با تعداد سناریوها به صورت تصاعدی رشد کند. با توجه به مشکلات در حل مسئله معادل قطعی ، الگوریتم های تجزیه مانند تجزیه Lagrangean (Guignard ، 2003 ؛ Oliveira et al. ، 2013) و تجزیه Benders (Van Slyke and Wets ، 1969 ؛ Laporte and Louveeaux ، 1993) قابل استفاده است. حل مسئله Eq. 2 به طور مؤثرتر
نمای سطح بالایی از ایده های موجود در تجزیه Benders و تجزیه Lagrangean در شکل 5 نشان داده شده است. شکل ساختارهای ماتریس محدودیت را نشان می دهد که ستون ها با متغیرها مطابقت دارند و ردیف ها با محدودیت ها مطابقت دارند. هر دو الگوریتم تجزیه از ساختار مورب "تقریبا" بلوک نشان داده شده در شکل 5 استفاده می کنند.
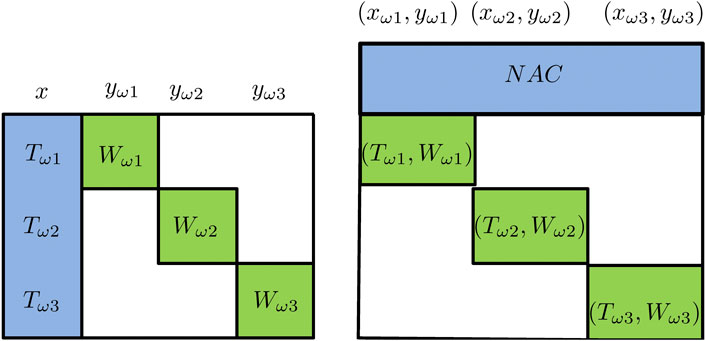
شکل 5نمای شماتیک از تجزیه خمرها (سمت چپ ؛ متغیرهای x "متغیرهای پیچیده" هستند) ، تجزیه Lagrangean (سمت راست ؛ NAC ها "محدودیت های پیچیده" هستند).
تجزیه Benders (Van Slyke and Wets ، 1969 ؛ Laporte and Louveaux ، 1993) ، همچنین به عنوان روش L شکل در ادبیات برنامه نویسی تصادفی گفته می شود ، متغیرهای مرحله اول را به عنوان "متغیرهای پیچیده" می بینندبقیه مشکل Eq را برطرف می کنند. 2 دارای یک ساختار مورب بلوک است که می تواند با سناریو تجزیه شود و به طور مستقل حل شود. یک دیدگاه شماتیک از ایده "متغیر پیچیده" در تجزیه و تحلیل Benders در شکل 5 نشان داده شده است. از نظر ریاضی ، الگوریتم تجزیه Benders با تعریف یک مشکل اصلی با تصمیمات مرحله اول آغاز می شود. پس از حل مشکل اصلی ، تصمیمات مرحله اول در راه حل بهینه مشکل اصلی ثابت می شوند. سپس مشکل معادل قطعی می تواند به | Ω | تجزیه شودSubproblems Where | Ω |نشانگر مهمترین مجموعه سناریوها است. Subproblems را می توان به صورت موازی حل کرد و نابرابری های معتبر X را می توان به دست آورد و به مشکل اصلی Benders اضافه شد. مشکل اصلی دوباره حل می شود و الگوریتم تکرار می شود تا حد بالایی و پایین همگرایی. حد پایین مقدار بهینه مشکل Master Benders است. قسمت بالایی با به روزرسانی بهترین راه حل امکان پذیر بدست می آید. تجزیه و تحلیل Benders قادر به همگرایی در تعداد محدودی از مراحل است که تصمیمات مرحله دوم مداوم و محدودیت های مرحله دوم خطی باشد.
تجزیه Lagrangean مشکل Eq را اصلاح می کند. 2 با تهیه نسخه ای از تصمیمات مرحله اول برای هر سناریو و اضافه کردن محدودیت های غیر پیشگیری کننده (NAC) برای اطمینان از تصمیمات مرحله اول که برای همه سناریوها گرفته شده است. به عنوان مثال ، در یک مشکل سه صحنه ، سه نسخه از متغیرهای X ، x Ω 1 ، x Ω 2 ، x Ω 3 ساخته شده است. NAC ها از جمله x ω 1 = x ω 2 ، x ω 1 = x ω 3 اضافه می شوند تا تصمیمات مرحله اول برای هر سه سناریو یکسان باشد. یک دیدگاه شماتیک از تجزیه Lagrangean نیز در شکل 5 نشان داده شده است. پس از این اصلاحات ، NAC S سپس دوگانه می شوند تا مسئله معادل قطعی به سناریوهایی تجزیه شود که به طور موازی قابل حل است. ضرب های Lagrangean را می توان با استفاده از روش Sublicient یا روش هواپیمای برش به روز کرد (Oliveira et al. ، 2013). در هر تکرار از تجزیه Lagrangean که جمع بندی مقدار بهینه از زیربناهای Lagrangean است ، می توان از حد پایین تر به دست آورد. با این حال ، روال حد بالایی تجزیه لاگرانژین به طور کلی اکتشافی است. بنابراین ، تجزیه Lagrangean تضمین نمی شود که حتی برای مشکلات مربوط به مراجعه مداوم همگرا شود. معمولاً یک "شکاف دوگانگی" بین قسمت فوقانی و پایین وجود دارد.
اگرچه نه خمرها و نه تجزیه Lagrangean قادر به حل EQ نیستند. 2 با متغیرهای مراجعه به عدد صحیح به بهینه با فرم کلاسیک آنها ، تحولات اخیر صورت گرفته است که می تواند Eq را حل کند. 2 برای بهینه سازی با گسترش این دو روش. بحث در مورد این پیشرفت های اخیر می تواند بسیار فنی باشد و ما خوانندگان علاقه مند را به مقالات مرور ، تورس و همکاران ارجاع می دهیم.(2019) ؛Küçükyavuz and Sen (2017) ، برای جزئیات.
در مورد اجرای نرم افزار ، حل کننده CPLEX اجرای الگوریتم تجزیه Benders Bonami و همکاران را دارد.(2020) ، که از طریق اکثر سیستم عامل های مدل سازی ، مانند GAMS ، C ، C ++ ، Pyomo (هارت و همکاران ، 2017) ، پایتون و غیره قابل دسترسی است. DSP (کیم و زاولا ، 2018) یک حل کننده مبتنی بر تجزیه Lagrangean استبرای برنامه های مخلوط تصادفی دو مرحله ای ، که رابط هایی را ارائه می دهد که می توانند مدل های بیان شده در کد C و قالب SMPS را بخوانند (Gassmann and Schweitzer ، 2001). DSP همچنین می تواند مدلهای بیان شده در پرش را بخواند (Lubin and Dunning ، 2015).
3. 2 برنامه های غیرخطی مخلوط تصادفی دو مرحله ای
بیشتر الگوریتم ها و برنامه های SP که توسط جامعه تحقیقات عملیات (OR) مورد بررسی قرار گرفته اند ، مشکلات خطی (مخلوط مخلوط) مانند Eq هستند. 2. با این حال ، برنامه های مهندسی شیمی می توانند شامل غیرخطی های قابل توجهی باشند. مثالها شامل معادلات تعادل جرم برای تقسیم کننده ها و میکسر در یک صفحه جریان ، معادلات مش در طراحی ستون تقطیر ، معادله Arrhenius در مدل سازی راکتور است. بنابراین ، توسعه مدل های برنامه نویسی تصادفی و الگوریتم های مربوط به مشکلات غیرخطی (مخلوط مخلوط) مورد توجه مهندسان شیمی که تحقیقات PSE را انجام می دهند ، بسیار مورد توجه است. در حقیقت ، جامعه PSE محرک اصلی توسعه الگوریتم ها برای حل کارآمد MinLP های تصادفی بوده است (لی و همکاران ، 2011b ؛ لی و گروسمن ، 2019b ؛ Cao و Zavala ، 2019).
3. 2. 1 فرمول ریاضی
فرمولاسیون ریاضی یک برنامه غیرخطی مخلوط تصادفی دو مرحله ای کلی در Eq نشان داده شده است. 5
مشکل Eq. 5 پسوند Eq است. 2 با در نظر گرفتن محدودیت های هدف غیرخطی و غیرخطی. توابع f0، f1، g0، g1در Eq5 توابع غیرخطی هستند. f1و g1توابع تصمیمات مرحله اول x ، تصمیمات مرحله دوم yωو پارامترهای نامشخص θωبرای سناریو ω. با توجه به هدف غیرخطی و محدودیت های غیرخطی ، Eq. 5 حل کردن از Eq دشوارتر است. 2. ما الگوریتم ها را برای حل EQ مرور خواهیم کرد. 5 در بخش 3. 2. 3.
3. 2. 2 نمونه مشکل استخر تصادفی
ما نمونه ای از مشکل استخر تصادفی ارائه شده در Li و Grossmann (2019b) را ارائه می دهیم. مشکل جمع آوری در برنامه های کاربردی شامل تصفیه فاضلاب (Karuppiah and Grossmann ، 2008) ، برنامه ریزی پالایشگاه نفت خام (یانگ و بارتون ، 2016) و برنامه ریزی شبکه های گاز طبیعی (لی و همکاران ، 2011a). حل مسئله جمع آوری بهینه به دلیل پس انداز احتمالی به ترتیب ده ها میلیون دلار مورد توجه بسیاری است. در یک مشکل استخر ، جریان های جریان از منابع مختلف در برخی از مخازن میانی (استخرها) مخلوط می شوند و دوباره در نقاط ترمینال مخلوط می شوند. در استخرها و پایانه ها ، کیفیت مخلوط به عنوان میانگین وزنی از خصوصیات جریان جریان که به درون آنها می روند ، داده می شود.
مشکل جمع آوری هم شامل تصمیمات طراحی و هم تصمیمات عملیاتی است. تصمیمات طراحی این است که من را تغذیه می کنند و کدام استخر L را برای انتخاب از روبنا نشان داده شده در شکل 6a و تصمیمات اندازه برای مخازن و استخرهای انتخاب شده انتخاب می کنند. تصمیمات مرحله دوم جریان جرم جریان های مختلف و کسری تقسیم می شود. اپراتور برای برآورده کردن مشخصات کیفیت در پایانه های محصول J (شکل 6A) باید فیدها و استخرها را کار کند. در این مشکل ، ما همچنین خرید فیدها را با استفاده از سه نوع قرارداد مختلف یعنی قیمت ثابت ، تخفیف پس از مبلغ معینی و تخفیف فله در نظر می گیریم.
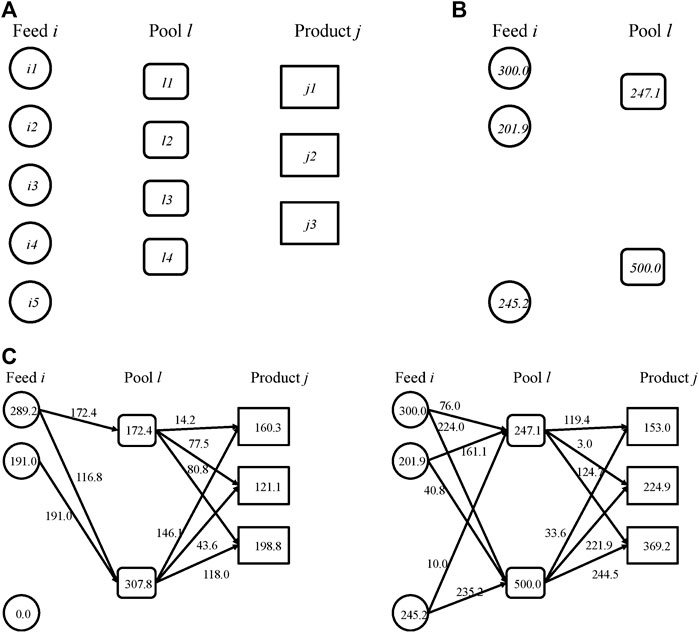
شکل 6. مشکل جمع آوری تصادفی (A) روبنا ساختار مشکل استخر است (B) تصمیمات بهینه مرحله اول برای مثال استخر (ج) نشان دهنده میزان بهینه جریان جرم در سناریوی کم تقاضا (سمت چپ) و تقاضای بالا استسناریو (سمت راست).
قبل از تصمیم گیری در مورد طراحی ، چندین منبع عدم قطعیت می تواند در سطح عملیاتی از جمله کیفیت جریان خوراک ، قیمت خوراک و محصولات ، تقاضا برای محصولات ایجاد شود. برای این مثال مصور ، ما فقط عدم اطمینان را در خواسته های محصولات در نظر می گیریم. خواسته های این سه محصول می تواند مقادیر کم ، متوسط و بالایی داشته باشد و فرض بر این است که به طور همزمان متفاوت است ، یعنی سه سناریو در این مشکل به ترتیب با احتمال 0. 3 ، 0. 4 ، 0. 3 وجود دارد. محصولات تحویل واقعی باید کمتر یا مساوی با خواسته ها باشند. هدف این است که حداکثر سود کل مورد انتظار را به حداکثر برساند. فرمول ریاضی این مشکل در لی و گروسمن (2019b) گزارش شده است. برای تهیه این مقاله ، ما فرمولاسیون ریاضی را در مواد تکمیلی قرار می دهیم.
معادل قطعی مشکل استخر تصادفی با سه سناریو به بهینه سازی حل می شود. تصمیمات بهینه در مرحله اول انتخاب فیدهای I است1، من2، من5، استخرهای L1، و من4وادظرفیت های بهینه خوراک و استخرهای انتخاب شده در شکل 6b نشان داده شده است. به یاد بیاورید که در برنامه نویسی تصادفی دو مرحله ای ، پس از تصمیمات مرحله اول ، خواسته های نامشخص تحقق می یابد. در سناریوهای مختلف ، بسته به تحقق تقاضا می توان اقدامات متفاوتی را انجام داد. میزان جریان جرم تمام جریان ها در سناریوهای زیاد و کم تقاضا را می توان در شکل 6c مشاهده کرد. هنگامی که تقاضا کم است ، مخازن خوراک و استخرها با ظرفیت کامل آنها کار نمی کنند. هنگامی که تقاضا زیاد باشد ، مخازن خوراک و استخرها با ظرفیت کامل خود کار می کنند. به یاد بیاورید که تولید هر محصول می تواند کمتر یا برابر با تقاضا باشد. در سناریوی پر تقاضا ، تولید محصول j1حتی در سناریوی کم تقاضا حتی پایین تر است. با این حال ، تولیدات J2و j3در سناریوی پر تقاضا بالاتر از سناریوی کم تقاضا هستند. نتایج همچنین نشان می دهد که ظرفیت بهینه برای تأمین تقاضای زیاد کافی نیست. دلیل این امر این است که اگر کسی تقاضای زیاد را به طور کامل برآورده کند ، بخش بزرگی از ظرفیت در سناریوی کم تقاضا بیکار خواهد بود. از طرف دیگر ، اگر این ظرفیت فقط برای برآورده کردن تقاضای کم به اندازه کافی طراحی شود ، در سناریوهای پر تقاضا و تقاضا متوسط از دست رفته قابل توجهی خواهد بود. برنامه نویسی تصادفی یک رویکرد "بی طرف ریسک" برای دستیابی به بالاترین سود مورد انتظار است که باعث می شود تجارت بین فروش از دست رفته و ظرفیت بیکار باشد.
3. 2. 3 الگوریتم برای حل minlp تصادفی
همانطور که در بخش 3. 1. 3 مورد بحث قرار گرفتیم ، الگوریتم های تجزیه کلاسیک ، مانند تجزیه Benders و تجزیه Lagrangean ، نمی توانند به راحتی برای حل MINLP های تصادفی اعمال شوند. چالش های حل مشکلات MINLP تصادفی دو برابر است: توابع غیرخطی در مرحله دو می توانند غیر کنفکس باشند. دوم ، برخی از متغیرهای مرحله دو باید محدودیت های یکپارچگی را برآورده سازند ، که این مرحله همچنین مرحله دو مشکل را بدون کنترل می کند. محققان جامعه PSE با توجه به کاربرد گسترده آن در سیستم های فرآیند ، الگوریتم هایی را برای حل مسئله Eq در حال توسعه هستند. 5- بسیاری از الگوریتم ها بر اساس الگوریتم های تجزیه کلاسیک از جمله تجزیه لاگرین و تجزیه خمیده های عمومی (GBD) (Geoffrion ، 1972) است که گسترش الگوریتم تجزیه Benders (BD) برای حل مشکلات غیر خطی است.
برای minlp تصادفی محدب ، که در آن منطقه غیرخطی امکان پذیر از آرامش مداوم محدب است ، لی و گروسمن (2018) یک روش بهبود یافته به شکل L را پیشنهاد می کنند که در آن زیرنویس های خمیده توسط رده های بلند و یک بالابر و برش محدب می شوند و برش های لاگراژنی هستند. برای محکم کردن مشکل اصلی Benders اضافه شده است. لی و گروسمن (2019a) بیشتر یک شاخه مبتنی بر تجزیه و تحلیل Benders و الگوریتم محدود را با همبستگی محدود برای minLP های تصادفی محدب با متغیرهای مرحله اول و دوم با دو با دودویی ارائه می دهند.
برای minlp تصادفی غیر کنفکس ، که در آن توابع غیرخطی در minlps تصادفی می تواند غیر کنسرت باشد ، کار پیشگام توسط لی و همکاران انجام می شود.. برای مورد کلی تر که متغیرهای مرحله اول می توانند مخلوط-مشخص شوند ، OGBE و LI (2019) یک الگوریتم تجزیه مشترک را پیشنهاد می کنند. یک شاخه کامل مبتنی بر اطلاعات و الگوریتم محدود که MINLP های تصادفی غیر قابل تفکیک را برای بهینه سازی جهانی حل می کند ، توسط Cao و Zavala (2019) ارائه شده است. Kannan (2018) یک شاخه اصلاح شده مبتنی بر آرامش Lagrangean (MLR) و الگوریتم محدود را پیشنهاد می کند ، و آنها ثابت می کنند که MLR دارای تغییر شکل محدود است. یک شاخه مبتنی بر تجزیه و تحلیل Benders و الگوریتم برش برای MinLP های تصادفی غیر کنفوست با متغیرهای مرحله اول و دوم با دوتایی مخلوط توسط لی و گروسمن (2019b) ارائه شده است. لی و همکاران.(2020) یک الگوریتم تقریبی بیرونی مبتنی بر میانگین نمونه را برای MinLP های تصادفی با توزیع احتمال مداوم پیشنهاد می کند.
4 برنامه نویسی تصادفی چند مرحله ای
در برنامه نویسی تصادفی دو مرحله ای ، فرض بر این است که عدم قطعیت ها فقط یک بار پس از تصمیمات مرحله اول تحقق می یابد. با این حال ، بیشتر مشکلات عملی شامل دنباله ای از تصمیمات است که به نتایج واکنش نشان می دهد که با گذشت زمان تکامل می یابد. تعمیم برنامه نویسی تصادفی دو مرحله ای به تحقق پی در پی عدم قطعیت ها "برنامه نویسی تصادفی چند مرحله ای" نامیده می شود. افق زمانی در "مراحل" گسسته می شود که در هر مرحله از تحقق عدم قطعیت در مرحله فعلی برخوردار است.
یک درخت سناریو شبیه به شکل 2 برای یک مشکل چند مرحله ای در شکل 7 نشان داده شده است. درخت سناریو دارای سه مرحله است. در مرحله دو ، دو تحقق متفاوت از پارامترهای نامشخص و بنابراین دو گره وجود دارد. هر یک از این دو گره بسته به تحقق اطلاعات تا مرحله دو ، می توانند دو مرحله متفاوت داشته باشند. پس از اتخاذ مرحله دو ، دو تحقق متفاوت از پارامترهای نامشخص در مرحله سه برای هر گره در مرحله دو وجود دارد. بنابراین ، در مرحله سه چهار گره در کل وجود دارد. تصمیمات مرحله سه به مرحله یک ، مرحله دو تصمیمات و تاریخ پارامترهای نامشخص بستگی دارد. یک سناریو در محیط چند مرحله ای "مسیری" از گره ریشه درخت سناریو به گره برگ درخت سناریو است ، که مربوط به تاریخچه کامل تحقق پارامترهای عدم اطمینان است تا مرحله سوم. به راحتی می توان دید که 4 سناریو در شکل 7 وجود دارد که با استفاده از ω نشان داده شده است1، ω2، ω3، ω4وادهفت گره در درخت سناریو به صورت متوالی با نماد n شماره گذاری شده است1- n7.
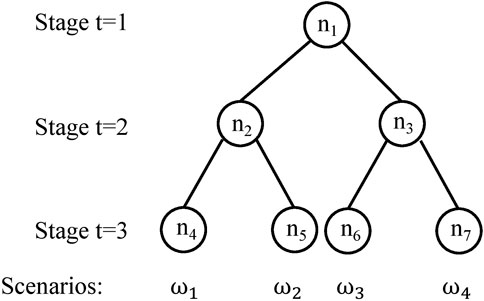
شکل 7تصویر یک درخت سناریو با 3 مرحله ، 4 سناریو ، هفت گره.
شایان ذکر است که در برخی از برنامه های PSE ، دو نوع تصمیمات یعنی تصمیمات استراتژیک به عنوان مثال ، نصب فرآیندهای شیمیایی و تصمیمات عملیاتی به عنوان مثال ، نرخ جریان مواد وجود دارد. عدم قطعیت ها می توانند از هر دو فرآیند تصمیم گیری استراتژیک و عملیاتی ناشی شوند. یک درخت سناریویی که دو نوع تصمیمات و عدم قطعیت ها را با هم ترکیب می کند ، می توان در Escudero و Monge (2018) یافت.
4. 1 فرمول ریاضی
فرمولاسیون برنامه نویسی تصادفی چند مرحله ای به شرح زیر آورده شده است (Birge and Louveaux ، 2011):
آموزش تحلیل گری...
ما را در سایت آموزش تحلیل گری دنبال می کنید
برچسب :
نویسنده : ملیکا زارعی
بازدید : 49
